Exercícios de Sistemas Operativos
Abaixo apresentamos propostas de resolução para uma seleção de perguntas do livro e de testes de anos anteriores.
- Capítulo 3 - Processos: Modelo Computacional
- Capítulo 4 - Gestor de Processos
- Capítulo 5 - Sincronização: Secções Críticas
- Capítulo 6 - Programação Concorrente [com memória partilhada]
- Capítulo 7 - Mecanismos de Gestão de Memória
- Capítulo 8 - Algoritmos de Gestão de Memória
- Capítulo 9 - Sistemas de Ficheiros
- Capítulo 10 - Comunicação Entre Processos
- Extra livro: Programação concorrente por troca de mensagens
Capítulo 3 - Processos: Modelo Computacional
Ex. 1 Considere o seguinte pseudo-código de um programa multitarefa com pthreads
(por simplicidade, omitem-se verificações de erros):
a) Que saídas são possíveis observar quando executamos este programa? Justifique. Assuma apenas execuções em que nenhuma das funções chamadas devolvem erro.
T1.1. int main(int argc, char **argv) {
T1.2. pthread_t tid;
T1.3. pthread_create(&tid, NULL, t2_start_routine, NULL);
T1.4. printf(“A\n”);
T1.5. pthread_join(tid, NULL);
T1.6. printf(“B\n”);
T1.7. return 0;
T1.8. }
T2.1. void *t2_start_routine(void *arg) {
T2.2. printf(“C\n”);}
T2.3. sleep(10); /* 10 segundos */
T2.4. return NULL;
T2.5. }
Tanto pode acontecer "A\nC\nB\n" como "C\nA\nB\n". A partir da linha em que a nova tarefa é criada, ambas as tarefas executam-se concorrentemente, logo não há garantia de ordem entre as execuções de cada uma, o que explica porque os printf das linhas T1.4 e T2.2 podem acontecer em qualquer ordem. Na linha T1.5, a tarefa original espera até a segunda tarefa terminar (linha T2.4), logo o printf da linha T1.6 acontecerá necessariamente depois dos outros printf (assumindo execução sem falhas).
b) Ao longo da execução do programa existirão diferentes conjuntos de tarefas em execução. Indique como evolui o conjunto de tarefas, relacionando com as linhas do programa acima.
Uma tarefa até à linha T1.3, duas tarefas até à linha T2.4, uma tarefa a partir desse momento (assumindo execução sem falhas).
c) Caso a tarefa t2 queira devolver uma cadeia de caracteres (char*) à tarefa original para esta a imprimir com printf, como deveria o programa ser alterado?
Na função t2_start_routine:
Na função main:
char *s = ...;
...
T2.4. return s;
char *s;
T1.5. pthread_join(tid, &s);
T1.6. printf("%s", s);
Ex. 2 - Considere um dado programa, com vários fios de execução, que tem 3 versões que se executam num computador uniprocessador com sistema operativo do tipo Unix e cuja funcionalidade não implica nenhuma operação de I/O:
- versão V1 em que cada fio de execução é suportado por um processo,
- versão V2 em que cada fio de execução é suportado por uma tarefa real, e
- versão V3 em que cada fio de execução é suportado por uma pseudo-tarefa.
Note que as 3 versões têm exatamente a mesma funcionalidade.
a) Como compara as versões V1 e V2 no que respeita à robustez do programa? Na sua resposta considere, por exemplo, que um dos fios de execução faz uma divisão por zero.
A versão V1 é mais robusta, uma vez que apenas o processo onde ocorre o erro é terminado, continuando as restantes tarefas a executar-se. Na versão V2 o processo (que inclui todas as tarefas) é terminado. No caso de uma divisão por zero, em V1, apenas o fio de execução associado ao processo onde ocorre a divisão por zero termina (e todos os outros fios de execução continuam a sua execução normal) enquanto que em V2, todos os fios de execução são terminados.
b) Como compara as versões V1 e V3 no que respeita à robustez do programa? Na sua resposta considere, por exemplo, que um dos fios de execução faz uma divisão por zero.
Resposta idêntica à anterior.
c) Como compara as versões V1 e V2 no que respeita à rapidez de execução do programa?
V1 será mais lento, pois a criação de processos e comutação entre processos é mais lenta que a criação/comutação entre tarefas, dado que os processos não partilham o mesmo contexto.
d) Como compara as versões V1 e V3 no que respeita à rapidez de execução do programa?
Resposta idêntica à anterior.
e) Considere agora que o programa é executado numa máquina com dois processadores. Compare o desempenho das versões V2 e V3.
A versão V2 será mais rápida pois diferentes tarefas poderão executar-se concorrentemente nos dois processadores. Na versão V3, todas as pseudotarefas irão partilhar um único processador.
Sugestão: Rever Secção 3.4.2 – Modelo Multitarefa
Ex. 3 Considere um sistema operativo do tipo Unix no qual um processo executa o seguinte programa que se encontra num ficheiro “t.c”; “t.c” é compilado gerando um ficheiro executável “t.exe”. Por simplicidade, omitem-se verificações de erros.
1. #include <stdio.h>
2. #include <stdlib.h>
3. main() {
4. int pid, pid_filho, status;
5. printf ("\nantes do fork pid=%d\n", getpid());
6. pid = fork();
7. if (pid == 0) {
8. printf ("pai=%d e filho=%d\n", getppid(), getpid());
9. execv ("t.exe",NULL);
10. }
11. else if (pid != -1){
12. pid_filho = wait(&status);
13. printf ("depois do wait feito pelo pid=%d obtendo pid_filho=%d\n", getpid(), pid_filho);
14. exit (0);
15. }
16. else {
17. printf ("erro no fork\n");
18. exit (-1);
19. }
20. }
a) Quantos processos são criados?
Serão criados continuamente processos, de forma recursiva, até que se esgotem os recursos da máquina ou que os limites de utilização de recursos pelo utilizador sejam atingidos.
b) Assuma que o fork nunca retorna erro. A instrução depois do “wait” é executada?
Assumindo uma máquina e utilizador com recursos infinitos (logo o programa acima é capaz de criar um número infinito de processos filho), nenhum processo filho chega a terminar (assumindo também que a chamada “exec” nunca falha). Consequentemente, a função “wait” nunca retornará, logo alinha seguinte nunca será executada.
c) Assuma que o fork retorna erro na 3ª vez que é chamado. Considere que inicia a execução do programa “t.exe”. Indique o seu output continuando o que se indica (antes do fork pid=2204).
antes do fork pid=2204
pai=2204 e filho=2205
antes do fork pid=2205
pai=2205 e filho=2206
antes do fork pid=2206
erro no fork
depois do wait feito pelo pid=2205 e obtendo pid_filho=2206
depois do wait feito pelo pid=2204 e obtendo pid_filho=2205
Os valores dos pids do processos apresentados podem ser outros pois isso depende do SO; no entanto, note que os valores em causa devem ser coerentes com a hierarquia dos processo em causa.
Sugestão: Rever Secção 3.5.2 - Operações sobre Processos
Ex. 4 É possível implementar o conceito de pseudoparalelismo sem recorrer ao núcleo do sistema operativo? Justifique.
Sim, é possível implementar o conceito de pseudoparalelismo através da utilização de co-rotinas ou pseudotarefas. A gestão das pseudotarefas é feita explicitamente pelo programador usando bibliotecas que se executam no espaço do utilizador, i.e., sem recorrer ao núcleo do sistema operativo. Em particular, a comutação de tarefas poderá ser feita: i) explicitamente, o que implica que o programador invoque a função de comutação de tarefa “yield”, ou ii) implicitamente através da utilização do mecanismo de exceções com base num intervalo de tempo que, quando expira, gera um signal que é tratado por uma rotina que efetuará a comutação de tarefas.
Sugestão: Rever Secção 3.4.2.2 - Conceito de tarefa
Ex. 5 Considere o seguinte excerto de um programa Unix (por simplicidade, omitem-se verificações de erros):
1. int a; /* variável global */
2. main() {
3. a = 0;
4. if (fork() == 0) {
5. a++;
6. printf(“%d”, a);
7. exit(0);
8. }
9. else {
10. pid = wait(&estado);
11. }
12. printf(“%d”, a);
13. }
a) Qual a saída deste programa? Justifique.
Saída: ‘10’. O primeiro algarismo (‘1’) é impresso após a criação do processo filho e depois do incremento unitário à variável ‘a’, que depois é impressa (linha 6). O segundo algarismo (‘0’) é impresso pelo processo pai depois do processo filho terminar (linha 12). É de notar que os processos não partilham o mesmo espaço de endereçamento, razão pela qual a variável ‘a’ possui valores distintos nos dois processos.
b) Modifique-o de modo a obter outra sequência. Por simplicidade, omita verificações de erros. Justifique.
Várias respostas possíveis. Possível resposta:
1. int a; /* variável global */
2. main() {
3. a = 0;
4. if (fork() == 0) {
5. a++;
6. printf(“%d”, a);
7. /* exit(0); */
8. }
9. else {
10. pid = wait(&estado);
11. }
12. printf(“%d”, a);
13. }
Saída: ‘110’. Os primeiros dois ‘1’s são impressos pelo filho (linhas 6 e 12). O ‘0’ é impresso pelo pai (linha 12). O valor da variável ‘a’ no processo pais é zero pois apenas o filho incrementa a variável (linha 5). Uma vez que os processos não partilham o mesmo espaço de endereçamento, um incremento de uma variável no filho não tem qualquer efeito no processo do pai.
Sugestão: Rever Secção 3.5.2 - Operações sobre Processos
Ex. 6 Para cada uma das seguintes afirmações, indique se esta pode ou não ser um motivo válido para a utilização de múltiplas tarefas reais (tarefas-núcleo) num programa que corre num sistema operativo Unix, e explique porquê:
a) Ter múltiplos fios de execução com espaços de endereçamento separados no mesmo programa.
Não; ao utilizar tarefas reais, o espaço de endereçamento é comum a todas as tarefas do mesmo processo.
b) Poder sobrepor a execução de instruções de E/S com a utilização do CPU por outras partes do mesmo programa.
Sim, ao utilizar tarefas reais, enquanto uma ou mais tarefas podem estar a tratar eventos de E/S, outras poderão estar a utilizar CPU.
c) Executar dois programas diferentes (correspondentes a diferentes ficheiros executáveis) em paralelo.
Não; tarefas reais não são necessárias para atingir paralelismo entre dois processos diferentes. As tarefas reais podem apenas trazer paralelismo dentro do mesmo processo (i.e., vários fios de execução em paralelo).
Sugestão: Rever Secção 3.4 – Modelos de Programação de Processos
Ex. 7 Considere o seguinte excerto de um programa que usa signals em Unix (por simplicidade, omitem-se verificações de erros):
1. void trata_signal(int num) {
2. signal(SIGINT, trata_signal);
3. printf(“Operação negada.”);
4. }
5.
6. int main(void) {
7. if (signal(SIGINT, trata_signal) == SIG_ERR)
8. {printf(“Erro no signal”);}
9. for (;;) {sleep(10);}
10. exit(0);
11.}
a) Explique o comportamento deste programa.
O programa começa por instalar uma rotina de tratamento para o sinal ‘SIGINT’ usando a chamada de sistema “signal” e fazendo o teste devido para verificar o retorno da chamada de sistema. De seguida, o programa entra num ciclo ”for” sem fim onde, a cada iteração, o programa suspende a sua execução durante 10 segundos (utilizando a chamada de sistema “sleep”). A rotina de tratamento do sinal “SIGINT”, se chamada, re-instala o sinal e imprime uma mensagem para a output. É de notar que o sinal “SIGINT” pode ser gerado através da combinação das teclas CTRL+C.
b) Identifique todas as funções do sistema operativo e da biblioteca stdio que são utilizadas no programa e explique o que faz cada uma.
“printf” – imprime carateres para o output do processo;
“signal” – instala rotinas de tratamento de sinais;
“sleep” – suspende a execução da tarefa atual durante um período de tempo;
“exit” – termina a execução do processo.
c) De que forma um processo que corra este programa pode ser terminado? Justifique.
O processo pode ser terminado enviando um sinal cujo efeito sobre o processo é terminá-lo. Por exemplo, é possível utilizar a chamada de sistema “kill” com o sinal “SIGTERM” para terminar este processo.
Sugestão: Rever Secção 3.5.3 - Signals
Ex. 8 Considere a chamada de sistema “kill” em Unix.
a) Explique o que faz esta função.
A chamada de sistema “kill” tem como propósito o envio de sinais a processos.
b) Esta função necessita de efetuar algumas validações de segurança. Explique quais e qual o motivo da sua existência.
Uma vez que a chamada de sistema “kill” pode interferir com outros processos, é importante garantir que, por exemplo, um utilizador sem privilégios de superutilizador não consiga interferir com processos do sistema (que estão associados ao superutilizador do sistema) ou com processos de outros utilizadores. Desta forma, usando a função de sistema “kill”, apenas é possível enviar sinais a processos do mesmo UID. Apenas processos com privilégios de superutilizador podem ultrCapassar esta proteção.
c) O nome desta primitiva é enganador. Explique porquê.
É enganador pois a função não mata o processo, apenas envia sinais. A possível motivação para o nome resulta da implementação por omissão do tratamento da maioria dos sinais, que resulta no término do processo.
Sugestão: Rever Secção 3.5.3.4 - Operações Associadas aos Signals
Ex. 9 Considere o seguinte código multitarefa (por simplicidade, omitem-se verificações de erros):
1. int i;
2. int main(int argc, char **argv) {
3. if (thread_create(t2_start_routine, (void*)0) == NULL) {exit(1);}
4. thread_yield(); /* comutação de tarefa */
5. for (i = 0; i < MAX; i++) {printf(“t1\n”);}
6. return 0;
7. }
8. void *t2_start_routine(void *arg) {
9. for (i = 0; i< MAX; i++) {printf(“t2\n”);}
10. sleep(10); /* 10 segundos */
11. return 0;
12. }
Suponha que as rotinas “thread_create” e “thread_yield” são implementadas por uma biblioteca de co-rotinas (pseudotarefas).
a) Qual é a saída deste programa? Justifique.
Saída: ‘MAX’ linhas com ‘t2’ seguidas de ‘MAX’ linhas com ‘t1’. Uma vez que este código usa pseudotarefas, cada tarefa vai executar-se (de acordo com o código apresentado) até que a outra chame a função “thread_yield” ou termine. Assim sendo, a thread que executa a rotina ‘t2_start_routine’ vai executar-se até terminar (daí as linhas com ‘t2’ serem impressas todas seguidas). A outra thread (que invocou a função “thread_yield”) apenas imprime linhas com ‘t1’ após a outra thread terminar.
b) A resposta à alínea anterior manter-se-ia se mudasse para tarefas reais? Justifique.
Não. Com tarefas reais, é possível que as linhas escritas por cada tarefa ficassem alternadas uma vez que é o núcleo do sistema operativo a decidir que tarefa corre em cada instante. Deste modo, como já não é o programador a decidir o escalonamento, ambas as tarefas vão executar-se concorrentemente.
c) Considerando ainda o código apresentado acima, consegue determinar o tempo mínimo que decorre entre a saída das diferentes tarefas? Qual é esse tempo mínimo? Justifique.
10 segundos é o tempo mínimo pois a tarefa que executa a função ‘t2_start_routine’ executa um “sleep” antes de terminar. É de notar que a tarefa ‘t2’ está a executar-se porque a tarefa ‘t1’ invocou a função “thread_yield”, que retira ‘t1’ de execução até que tarefa ‘t2’ termine.
d) A resposta à alínea anterior manter-se-ia se mudasse para tarefas reais? Justifique.
Não, com tarefas reais, a saída de ambas as tarefas pode sair alternada pois a chamada a “thread_yield” apenas faz com que a thread perca o tempo de CPU que lhe foi atribuído no último escalonamento. Desta forma, é possível que venha a ser escalonada novamente antes da thread ‘t2’ terminar.
Sugestão: Rever Secção 3.5.4 - Tarefas-Interface POSIX
Ex. 10 Considere o código do seguinte programa Unix (por simplicidade, omitem-se verificações de erros):
1. #include <stdio.h>
2. int a;
3. fn() {
4. a++;
5. printf(“X %d\n”, a);
6. exit(0);
7. }
8.
9. main(int argc, char **argv) {
10. int val;
11. a = 0;
12. printf(“Y %d\n”, a);
13. if (fork() == 0) {fn();}
14. wait(&val);
15. printf(“Z %d\n”, a);
16. }
a) Qual a saída deste programa? Se houver mais do que uma possibilidade, indique todas as possíveis saídas.
Saída possível 1:
‘Y 0
X 1
Z 0’
Saída possível 2 (se o “fork” falhar):
‘Y 0
Z 0’
b) Escreva um novo programa que seja equivalente (no sentido de executar a mesma sequência de código, apesar de não ter necessariamente a mesma saída), exceto no seguinte aspeto: na linha 13 deve lançar uma nova tarefa em vez de um novo processo. Deve utilizar a interface POSIX para todas as funções relacionadas com as tarefas. Tenha o cuidado de atualizar as restantes funções do sistema operativo que são invocadas neste código em conformidade. Por simplicidade, omita verificações de erros.
1. #include <stdio.h>
2. int a;
3. void *fn(void *arg) {
4. a++;
5. printf(“X %d\n”, a);
6. return 0;
7. }
8.
9. main(int argc, char **argv) {
10. pthread_t tid;
11. a = 0;
12. printf(“Y %d\n”, a);
13. pthread_create(&tid, NULL, fn, NULL);
14. pthread_join(tid, NULL);
15. printf(“Z %d\n”, a);
16. }
c) Qual a saída do novo programa?
Saiída possível 1:
‘Y 0
X 1
Z 1’
Saída possível 2 (se o “pthread_create” falhar):
‘Y 0
Z 0’
d) Ordene em termos de velocidade de comutação, da mais rápida para a mais lenta, as seguintes possibilidades para a execução deste programa:
- Usando tarefas núcleo;
- Usando pseudotarefas;
- Usando processos;
Pseudotarefas, tarefas núcleo, processos.
e) Para a resposta anterior, explique a razão principal para a escolha relativa entre as tarefas núcleo e as pseudotarefas.
A principal razão prende-se com o facto da comutação de tarefas reais implicar mais custo do que a comutação de pseudotarefas pois no primeiro caso é preciso passar de modo de utilizador para modo núcleo e vice versa enquanto que no segundo caso a comutação apenas em modo de utilizador.
Sugestão: Rever Secção 3.4 – Modelos de Programação de Pocessos
Capítulo 4 - Gestor de Processos
Ex. 1 Considere o seguinte diagrama de estados básico dos processos num sistema operativo.
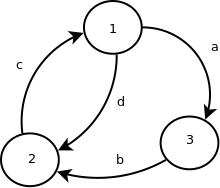
a) Escreva uma legenda para o diagrama (não se esqueça de indicar o nome dos estados bem como explicar as transições);
1 - Em Execução
2 - Executável
3 – Bloqueado
a – O processo em execução bloqueia-se num objeto do sistema operativo (por exemplo, trinco, semáforo ou variável de condição) à espera duma condição que, sem a qual, não pode avançar.
b – A condição que estava a bloquear o processo (trinco, semáforo ou variável de condição, por exemplo) verifica-se e o processo passa ao estado Executável;
c – O processo em execução libertou o processador (porque expirou o seu quantum ou por se ter bloqueado), tendo o despacho colocado um outro processo executável em execução;
d – Outro processo no estado executável tem maior prioridade e é comutado pelo escalonador.
b) O diagrama não inclui um estado presente no Unix denominado zombie. Explique porque é necessário este estado, ou seja, por que motivo o Unix não elimina o contexto de um processo mal este termina;
O estado zombie é atingido quando um processo P termina. Neste momento, o núcleo do SO elimina as estruturas de dados referentes ao processo que terminou ( i.e. o seu contexto) à exceção da estrutura que guarda o valor de retorno da função exit (que resultou no término do processo). Esta informação é necessária para o pai do processo P conseguir obter a informação do término através da chamada de sistema wait (e que foi passado como argumento na função exit) Aquando da chamada à função wait, o núcleo do SO verifica se existe algum processo filho no estado zombie.
Sugestão: Rever Secção 4.2 – Representação dos Processos
Ex 2. Considere dois algoritmos de escalonamento multi-lista, um com prioridades fixas e outro igual ao do Linux. Para cada uma das seguintes situações, indique qual escalonador escolheria e por que motivo.
a) Suporte para processos interativos;
Escalonador do Unix, visto que este usa prioridades dinâmicas que beneficiam processos que usem pouco tempo de processador. Deste modo, processos interativos (i.e., E/S intensivos) são favorecidos no acesso ao processador comparativamente a processos CPU intensivos.
b) Minimização da complexidade da implementação do escalonador.
É mais simples implementar um escalonador com prioridades fixas visto que, ao contrário de um escalonador com prioridades dinâmicas, não é necessário realizar cálculos complexos para atualizar a prioridade de cada processo nem manter múltiplas filas.
Sugestão: Rever Secções 4.3.2 e 4.4.6 – Escalonamento
Ex. 3 Suponha que num sistema operativo estão a correr dois processos. O processo P2 é CPU intensivo (não realizando qualquer operaçãos de E/S) e o processo P1 executa o seguinte código:
main() {
while(!terminado) {
trabalhoCPU(); // Requer uma unidade de tempo de CPU
trabalhoCPU(); // Requer uma unidade de tempo de CPU
efetuaES(); // Operação de E/S com duração de 2 unidades de tempo
// (quando chamada, bloqueia imediatamente durante 2 unidades de tempo)
trabalhoCPU(); // Requer uma unidade de tempo de CPU
}
}
Os processos têm as seguintes características:
| Processo | Prioridade Base | Instante de Início de Execução | Tempo Total de CPU |
|---|---|---|---|
| P1 | 10 | 0 | 6 (duas iterações completas do while) |
| P2 | 11 | 3 | 3 |
Nota: a coluna Tempo Total de CPU denota o tempo que o processo irá consumir durante toda a sua execução.
Suponha que:
- O algoritmo de escalonamento utilizado é preemptivo, com prioridades dinâmicas (em que um valor numérico de prioridade mais elevado corresponde a um processo mais prioritário);
- A prioridade de um processo começa por ser sua prioridade base, sofrendo um aumento de três unidades sempre que o processo sai do estado bloqueado;
- A prioridade do processo diminui uma unidade após cada quantum (time-slice) em que o processo tenha estado em execução, até atingir novamente a prioridade base:
- Se dois processos tiverem igual prioridade, o escalonador escolhe o que não é executado há mais tempo;
- A duração do quantum é de uma unidade de tempo;
Preencha a seguinte tabela, indicando, para cada time-slice, qual o estado de cada processo do sistema, e a respetiva prioridade no início do quantum. Utilize a seguinte notação: Letra E – Em execução; Letra B – Bloqueado; Letra V – Executável; Entrada em branco – processo não está ativo no sistema (não iniciou ou já terminou).
Note que na solução correta não é necessário utilizar mais espaço do que o fornecido.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | E (10) | E (10) | E>B (10) | B (10) | E (13) | E (12) | V (11) | E (11) | E>B (10) | B (10) | E (13) | |||
| P2 | E (11) | V (11) | V (11) | E (11) | V (11) | E (11) |
Nota: nas time-slices 2 e 8, são representadas as transições do estado E para o estado B dado que, no início de cada uma dessas time-slices, o processo está em execução; no entanto, ao chamar a função efetuaES, este é bloqueado de seguida.
Sugestão: Rever Secções 4.3.2 e 4.4.6 – Escalonamento
Ex 4. Suponha que num sistema operativo estão a correr três processos. Dois deles (P2 e P3) são CPU intensivos (não executam quaisquer operações de E/S) e o processo P1 executa o seguinte código:
main() {
while (! terminado) {
trabalhoCPU(); // Requer uma unidade de tempo de CPU
efetuaES(); // Bloqueia imediatamente e desbloqueia ao fim de 3 unidades de tempo
trabalhoCPU(); // Requer uma unidade de tempo de CPU
}
}
Os processos têm as seguintes características:
| Processo | Prioridade | Instante de Início de Execução | Tempo Total de CPU |
|---|---|---|---|
| P1 | 20 | 0 | 6 |
| P2 | 15 | 2 | 8 |
| P3 | 30 | 8 | 4 |
Nota: a coluna Tempo Total de CPU denota o tempo que o processo irá consumir durante toda a sua execução.
a) Suponha que o algoritmo de escalonamento utilizado é preemptivo, com prioridades fixas (em que o valor numérico de prioridade mais elevado corresponde a um processo mais prioritário). Preencha a seguinte tabela, indicando, para cada instante de tempo, qual o estado de cada processo do sistema.
Utilize a seguinte notação: Letra E – Em execução; Letra B – Bloqueado; Letra V – Executável; Entrada em branco – processo não está ativo no sistema (não iniciou ou já terminou).
Note que na solução correta não é necessário utilizar mais espaço do que o fornecido.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | E | E>B | B | B | E | E | E>B | B | B | V | V | V | E | E | E>B | B | B | E | ||
| P2 | E | E | V | V | E | E | V | V | V | V | V | V | E | E | E | V | E | |||
| P3 | E | E | E | E |
b) Preencha uma nova tabela, mas agora supondo que o algoritmo de escalonamento utilizado era o de time-slices em round-robin Todos os processos têm igual prioridade e com um time-slice a durar uma unidade de tempo.
Suponha que, ao sair do estado Bloqueado, ou ao iniciar, um processo vai para o final da lista dos processos executáveis.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | E | E>B | B | B | V | E | V | E | E>B | B | B | V | E | V | V | E | E>B | B | B | E |
| P2 | E | E | E | V | E | V | V | E | V | E | V | V | E | V | V | E | ||||
| P3 | E | V | E | V | V | E | V | V | E |
Nota: na time-slice 8, também é aceitável colocar P2 em execução já que, quer P2 quer P3 são colocados no final da lista de processos executáveis.
c) Indique uma desvantagem do algoritmo de round-robin (sem prioridades). Explique essa desvantagem usando o exemplo da pergunta anterior.
O algoritmo sem prioridades apresenta a desvantagem de escalonar os processos de uma forma que não favorece os processos que realizam E/S. É possível ver este efeito no exemplo anterior ao verificar que o processo P1 (que realiza E/S) é o último a terminar.
d) Explique de que forma um algoritmo com prioridades dinâmicas (tomando como exemplo o do Unix) resolve esse problema.
Os algoritmos com prioridades dinâmicas tendem a favorecer processos que utilizam menos o processador, i.e, dão prioridade no acesso ao processador os processos que pouco o utilizam, por exemplo processos E/S intensivos.
Sugestão: Rever Secções 4.3.2 e 4.4.6 – Escalonamento
Capítulo 5 – Sincronização: Secções Críticas
Ex. 1 No âmbito das soluções que asseguram a exclusão mútua, diga em que consiste a noção de míngua (starvation). Como se devem comportar as soluções corretas no que diz respeito à míngua?
A noção de míngua (ou starvation) refere-se à situação onde uma ou mais tarefas, que pretendem aceder a um recurso, não o conseguem, sistematicamente sendo ultrapassadas por outras tarefas que lhe acedem (mesmo que estejam há menos tempo à espera de entrar). Uma solução correta relativamente à míngua deve garantir que todas as tarefas têm igual oportunidade de acesso ao recurso em causa, não havendo preferências ou prioridades na seleção de tarefas a entrar na secção crítica.
Sugestão: Rever Secção 5.2 – Requisitos de uma Secção Crítica.
Ex. 2 Diga o que entende por espera ativa numa solução para o problema da secção crítica.
Espera ativa numa solução para o problema da secção crítica significa que um ou mais fios de execução estão continuamente a testar uma condição de entrada na secção crítica e essa condição só se alterará se o fio de execução deixar de efetuar esse mesmo teste. A utilização de espera ativa é muito comum em soluções algorítmicas para exclusão mútua (e é uma desvantagem clara relativamente a soluções com base em objetos do sistema operativo que não ocupam o processador de forma inútil enquanto a condição de espera não varia).
Sugestão: Rever Secção 5.3 – Exclusão Mútua Algorítmica.
Ex. 2 Considere um sistema operativo em que, durante a sequência de teste e modificação de uma variável partilhada (trinco), a exclusão mútua é conseguida através da inibição das interrupções. Diga qual a desvantagem desta solução.
Existem várias desvantagens:
- não funciona em multiprocessadores;
- só funciona dentro do núcleo;
- só é aceitável com secções críticas muito pequenas;
- torna o sistema vulnerável a bugs dentro da secção crítica.
Seguestão: Rever Secção 5.4.1 – Inibição de Interrupções.
Ex. 4 Para resolver os problemas da secção crítica há três tipos de solução possíveis, que diferem consideravelmente nos recursos que implicam, no desempenho e na sua facilidade de utilização no modelo computacional. Diga quais são e apresente as vantagens/desvantagens comparativas.
Secções críticas podem der implementadas de três formas diferentes:
1. algoriticamente. Esta solução apenas usa leituras e escritas de varáveis; no entanto, é difícil/complexa de usar na criação de programas e possui limitações relativamente ao número de tarefas que suporta e, mais grave ainda, implica a utilização de espera ativa;
2. baseada no hardware, que pode ser feita via inibição de interrupções ou usando instruções especiais. A primeira apenas pode ser utilizada em modo núcleo, em pequenos trechos de código e em sistemas com um único processador. A segunda pode ser usada com multiprocessadores e pode ser usada em modo de utilizador. No entanto, requer instruções especiais (do tipo test-and-set) e requer que o processo fique em espera ativa (testanto a variável do trinco);
3. utilizando objetos de sincronização (trincos e semáforos) suportados pelo núcleo. Esta solução combina as vantagens da solução anterior e permite evitar a espera ativa.
Seguestão: Rever Secções 5.3 (Exclusão Mútua Algorítmica), 5.4 (Exclusão Mútua Baseada no Hardware), e 5.5 (Exclusão Mútua com Objetos de Sincronização).
Capítulo 6 – Programação Concorrente [com memória partilhada]
Sugestão para todos os exercícios abaixo: Rever Secção 6.3 – Exemplos de Programação Concorrente e "An introduction to programming with threads (mutexes & condition variables)" (bibliografia adicional).
Ex. 1 Considere uma garagem na qual existem N lugares de estacionamento. A garagem tem várias entradas, sendo o acesso gerido por uma aplicação central com múltiplas tarefas. Cada tarefa é responsável por interagir com um terminal em cada entrada da garagem. Cada carro com acesso ao parque é identificado por um inteiro.
Cada condutor que se aproxima de uma entrada executa a função ocupar_lugar, implementada como de seguida, para reservar um lugar antes de entrar, e chama liberta_lugar quando sai da garagem. O vetor lugares[N] mantém o estado de cada lugar; a cada momento, cada entrada no vetor pode conter o valor LIVRE ou o identificador do carro que tem direito a ocupar o lugar.
int lugares[N] = {LIVRE, ..., LIVRE}; /* todos os elementos estão LIVRES */
1. int ocupa_lugar(int carId) {
2. int i;
3. for (i=0; i<N; i++) {
4. if (lugares[i] == LIVRE) {
5. lugares[i] = carId;
6. return i;
7. }
8. }
9. return -1;
10. }
11. void liberta_lugar(int carId) {
12. int i;
13. for (i=0; i<N; i++) {
14. if (lugares[i] == carId) {
15. lugares[i] = LIVRE;
16. return;
17. }
18. }
19. }
a) Após a inauguração do sistema, verificaram-se situações de conflitos entre condutores que reclamaram que, tendo acedido à garagem concorrentemente por entradas diferentes, lhes tinha sido atribuído o mesmo lugar. Analisando a implementação acima, indique a razão deste erro. Ilustre-a com um cenário concreto de execução que leve a esta situação indesejada.
Duas tarefas chamam ocupa_lugar concorrentemente, observando ambas o lugar 0 livre (linha 4, primeira iteração do ciclo) antes de alguma marcar o lugar como ocupado (linha 5), logo ambas ocupam esse lugar.
b) Proponha uma correção ao programa. Na sua solução não deve recorrer a espera ativa.
int lugares[N] = {LIVRE, ..., LIVRE}; /* todos os elementos estão LIVRES */
trinco t;
1. int ocupa_lugar(int carId) {
2. int i;
3. fechar(t);
4. for (i=0; i<N; i++) {
5. if (lugares[i] == LIVRE) {
6. lugares[i] = carId;
7. abrir(t);
8. return i;
9. }
10. }
11. abrir(t);
12. return -1;
13. }
14. void liberta_lugar(int carId) {
15. int i;
16. fechar(t);
17. for (i=0; i<N; i++) {
18. if (lugares[i] == carId) {
19. lugares[i] = LIVRE;
20. abrir(t);
21. return;
22. }
23. }
24. abrir(t);
25. }
c) Sempre que a função ocupa_lugar é chamada mas a garagem está cheia, a função deve esperar até que um lugar esteja finalmente disponível. Partindo da solução anterior, estenda ambas as funções para cumprir este novo requisito usando variáveis de condição.
int lugares[N] = {LIVRE, ..., LIVRE}; /* todos os elementos estão LIVRES */
int livres = N;
trinco t;
varcond condLugar;
1. int ocupa_lugar(int carId) {
2. int i;
3. fechar(t);
4. while (livres == 0)
5. wait(condLugar, t);
6. for (i=0; i<N; i++) {
7. if (lugares[i] == LIVRE) {
8. lugares[i] = carId;
9. livres --;
10. abrir(t);
11. return i;
12. }
13. }
14. abrir(t); //Nunca deverá chegar aqui
15. return -1;
16. }
17. void liberta_lugar(int carId) {
18. int i;
19. fechar(t);
20. for (i=0; i<N; i++) {
21. if (lugares[i] == carId) {
22. lugares[i] = LIVRE;
23. livres ++;
24. signal(condLugar);
25. abrir(t);
26. return;
27. }
28. }
29. abrir(t);
30. }
d) Suponha que uma tarefa T1 chamou ocupa_lugar mas a garagem estava cheia, o que colocou T1 à espera. Quando, de seguida, uma tarefa T2 chamou liberta_lugar. A sua solução permite que uma terceira tarefa, T3, que chame ocupa_lugar depois de T1 se ter colocado em espera possa ganhar um lugar antes de T1?
Sim. Quando T2, ao libertar um lugar, chama a função signal para desbloquear T1, T1 ainda precisará de readquirir o trinco para avançar na secção crítica e ocupar o lugar que ficou livre. No entanto, caso T3 tente obter o trinco nesse momento, é possível que o trinco seja obtido por T3 (que conseguirá assim ocupar o lugar livre) antes de T1 o obter; caso isso aconteça, T1 verificará que a condição livres==0 ainda se verifica, logo voltará a bloquear-se na variável de condição.
Ex. 2 Considere o seguinte problema:
- existem múltiplas tarefas que por vezes podem querer enviar (produtoras) ou receber (consumidoras) mensagens para/de um canal partilhado;
- o canal tem a capacidade N e é implementado como um buffer circular;
- a função ‘envia’ permite enviar múltiplas mensagens para o canal de uma só vez, sendo as mensagens colocadas de forma consecutiva no buffer circular; se não houver espaço suficiente, a função envia espera até que haja;
- a função recebe permite receber a próxima mensagem disponível no canal; se o canal estiver vazio, a função espera até chegar uma mensagem.
Considere a seguinte implementação de uma solução para o problema em causa (em pseudo-código):
1. Message canal[N];
2. int livre = N;
3. int envia_ptr=0, recebe_ptr=0;
4.
5. envia(Message messages[], int numMsg) {
6. while ( livre < numMsg);
7. for each (Message m in messages) {
8. canal[envia_ptr] = m;
9. envia_ptr = (envia_ptr+1) % N;
10. livre--;
11. }
12. }
13. Message recebe() {
14. while ( livre == N);
15. Message m = canal[recebe_ptr];
16. recebe_ptr = (recebe_ptr+1) % N;
17. livre++;
18. return m;
19. }
Ex. 2.1 Usando a solução acima apresentada num computador mono-processador, houve utilizadores que detetaram situações anómalas. Para cada situação anómala apresentada abaixo, explique se e porque pode acontecer, ilustrando com um exemplo de execução que produza o mesmo sintoma.
a) “Dois produtores produziram 1 item cada; no entanto, os consumidores apenas encontraram 1 item para consumir.”
Considerem-se dois produtores P1 e P2 a executar “envia” de forma concorrente. P1 perde o processador depois de executar a linha 06 e antes de executar a linha 08. Posteriormente P2 executas essas linhas, escrevendo na mesma posição que P1 (ver secção 6.3.4 do livro).
b) “Quando um produtor tenta colocar um item no buffer, e este está vazio e há vários consumidores a tentar consumir, o produtor demora muito mais tempo a concluir a operação (do que demoraria se não houvesse consumidores à espera de itens).”
Exemplo semelhante ao anterior, para dois consumidores e perca de processador entre as linhas 13 e 14.
Ex. 2.2 Proponha uma solução, em pseudo-código, que elimine ou minimize os problemas apontados acima.
a) Na sua solução recorra a trincos lógicos e/ou semáforos. No caso dos semáforos, considere que estes suportam as seguintes operações:
- esperar (identificador_do_semaforo, numero_de_unidades);
- assinalar (identificador_do_semaforo, numero_de_unidades).
Solução:
1. Message canal[N];
2. int livre = N;
3. int envia_ptr=0, recebe_ptr=0;
4. pode_enviar = criar_semaforo(N),
5. pode_receber = criar_semaforo(0);
6. trinco_enviar = cria_trinco();
7. trinco_receber = cria_trinco();
8. envia(Message messages[], int numMsg) {
9. esperar(pode_enviar, numMsg);
10. fechar(trinco_enviar);
11. for each (Message m in messages) {
12. canal[envia_ptr] = m;
13. envia_ptr = (envia_ptr+1) % N;
14. livre--;
15. }
16. abrir(trinco_enviar);
17. assinalar (pode_receber, numMesg);
18. }
19. Message recebe() {
20. esperar(pode_receber,1);
21. fechar(trinco_receber);
22. Message m = canal[recebe_ptr];
23. recebe_ptr = (recebe_ptr+1) % N;
24. livre++;
25. abrir(trinco_receber);
26. assinalar(pode_enviar,1);
27. return m;
28. }
b) Explique como é que a solução que apresentou resolve cada um dos comportamentos anómalos apontados acima para a primeira solução (1.a., 1.b, 1.c).
1.a e 1.b são resolvidos garantindo a exclusão mútua no acessos os índices e 1.c é resolvido evitando as esperas ativas com esperas bloqueantes com semáforos.
c) Diga se a sua solução permite que mensagens sejam enviadas e recebidas por tarefas distintas que usam índices distintos do vetor, permitindo assim um maior grau de concorrência. Altere a sua solução se necessário.
Sim, uma vez que o trinco que protege o índice de escrita é diferente do trinco que protege o índice de leitura. Este nível de concorrência não poderia ser atingido caso fosse usado um único trinco.
Ex. 3 Considere que numa empresa existem duas impressoras ligadas a uma rede com vários clientes. Cada impressora recebe pedidos de impressão num tampão circular associado a essa impressora. Enquanto houver pedidos no respetivo tampão, a impressora retira-os do tampão e imprime os respetivos trabalhos. Quando já não existirem pedidos no seu tampão, a impressora fica à espera. Quando os computadores querem imprimir, colocam o pedido no tampão que tiver um menor número de pedidos. Se os dois tampões estiverem cheios, então os computadores ficam à espera.
Usando trincos e variáveis de condição, implemente as rotinas void ColocaPedido(Pedido p) e Pedido ObtemPedido(int id), em que a primeira é chamada pelo o computador que pretende imprimir um trabalho e a segunda é chamada por uma impressora para retirar um pedido de impressão da fila de acordo com o exemplo abaixo. Nota: o parâmetro id identifica a impressora (0 ou 1). Na sua solução pode omitir o tratamento de erros.
1. void Impressora(int id) {
2. Pedido p;
3. while (1) {
4. p = ObtemPedido(id);
5. Imprime(p);
6. }
7. }
Solução:
#define N 10
Pedido pedidos[2][N];
int prod_idx[2] = {0, 0};
int cons_idx[2] = {0, 0};
int numPedidos[2] = {0, 0};
pthread_cond_t pode_cons[2];
pthread_cond_t pode_prod;
pthread_mutex_t mutex;
void ColocaPedido(Pedido p) {
int id;
pthread_mutex_lock(&mutex);
while (numPedidos[0]+numPedidos[1]==N*2)
pthread_cond_wait(&pode_prod, &mutex);
if (numPedidos[0] < numPedidos[1])
id = 0;
else
id = 1;
pedidos[id][prod_idx[id]] = p;
prod_idx[id] = (prod_idx[id] + 1) % N;
numPedidos[id]++;
pthread_cond_signal(&pode_cons[id]);
pthread_mutex_unlock(&mutex);
}
Pedido ObtemPedido(int id) {
pthread_mutex_lock(&mutex);
while (numPedidos[id] == 0)
pthread_cond_wait(&pode_cons[id], &mutex);
Pedido p = pedidos[id][cons_idx[id]];
cons_idx[id] = (cons_idx[id] + 1) % N;
numPedidos[id] --;
pthread_cond_signal(&pode_prod);
pthread_mutex_unlock(&mutex);
}
int main() {
pthread_cond_init(&pode_cons[0], NULL);
pthread_cond_init(&pode_cons[1], NULL);
pthread_cond_init(&pode_prod, NULL);
pthread_mutex_init(&mutex, NULL);
...
}
Ex. 4 Pretende-se construir uma aplicação em que tarefas produtoras enviam mensagens para uma tarefa consumidora. As mensagens são colocadas em quatro filas, cada uma associada a um nível de prioridade (podíamos considerar mensagens com quatro níveis de urgência). As mensagens são todas do mesmo tamanho e as filas de mensagens têm espaço para três mensagens.
Quando uma produtora pretende escrever a mensagem e a fila está cheia, fica bloqueada. A tarefa consumidora retira a mensagem da fila mais prioritária. Se não houver mensagens, deve ficar bloqueada. Programe as duas rotinas que permitem inserir e retirar mensagens:
void inserir(int Prioridade, struct mens m);
struct mens retirar();
Para simplificar, considere as seguintes estruturas:
‘struct mens’ para representar as mensagens;
‘struct mens[NUM_NIVEIS][TAMANHO] buffer’ para representar as filas de mensagem, NUM_NIVEIS corresponde ao nível de prioridade e TAMANHO ao número máximo de mensagens por fila.
a) Utilize variáveis de condição e trincos para sincronizar as tarefas.
Solução:
1. int prodptr[NUM_NIVEIS]; //inicializado a 0
2. int consptr[NUM_NIVEIS]; //inicializado a 0
3. int num_msgs[NUM_NIVEIS]; //inicializado a 0
4. pthread_cond_t filas_prod[NUM_NIVEIS];
5. pthread_cond_t fila_cons;
6. pthread_mutex_t mutex;
7. void inserir(int prioridade, struct mems m) {
8. pthread_mutex_lock(&mutex);
9. while (num_msgs[prioridade] == TAMANHO)
10. pthread_cond_wait(&fila_prod[prioridade], &mutex);
11. mens[prioridade][prodptr[prioridade]++] = m;
12. if (prodptr[prioridade] == TAMANHO) { prodptr[prioridade] = 0; }
13. num_msgs[prioridade]++;
14. pthread_cond_signal(&fila_cons);
15. pthread_mutex_unlock(&mutex);
16. }
17. struct mens retirar() {
18. struct mens res = NULL;
19. pthread_mutex_lock(&mutex);
20. while (soma(num_mgs, NUM_NIVEIS)==0) //soma todos os valores do array
21. pthread_cond_wait(&fila_cons, &mutex);
20. for (int nivel = 0; nivel < NUM_NIVEIS; nivel++) {
21. if (num_msgs[nivel] > 0) {
22. res = mens[nivel][consptr[nivel]++];
23. if (consptr[nivel] == TAMANHO) { consptr[nivel] = 0; }
24. pthread_cond_signal(&filas_prod[nivel]);
25. break;
26. }
27. }
28. pthread_mutex_unlock(&mutex);
29. return res;
30. }
32. int main() {
33. pthread_cond_init(&fila_cons, NULL);
34. for(int i=0; i<NUM_NIVEIS; i++) {pthread_cond_init(&filas_prod[i], NULL); }
35. pthread_mutex_init(&mutex, NULL);
...
}
b) Utilize semáforos e trincos para sincronizar as tarefas.
Solução:
1. int prodptr[NUM_NIVEIS];
2. int consptr[NUM_NIVEIS];
3. int num_msgs[NUM_NIVEIS];
4. sem_t filas_prod[NUM_NIVEIS];
5. sem_t fila_cons;
6. pthread_mutex_t mutex;
7. void inserir(int prioridade, struct mems m) {
8. sem_wait(&filas_prod[prioridade]);
9. pthread_mutex_lock(&mutex);
10. mens[prioridade][prodptr[prioridade]++] = m;
11. if (prodptr[prioridade] == TAMANHO) { prodptr[prioridade] = 0; }
12. num_msgs[prioridade]++;
13. pthread_mutex_unlock(&mutex);
14. sem_post(&fila_cons);
15. }
16. struct mens retirar() {
17. struct mens res = NULL;
18. sem_wait(&fila_cons);
19. pthread_mutex_lock(&mutex);
20. for (int nivel = 0; nivel < NUM_NIVEIS; nivel++) {
21. if (num_msgs[nivel] > 0) {
22. res = mens[nivel][consptr[nivel]++];
23. if (consptr[nivel] == TAMANHO) { consptr[nivel] = 0; }
24. sem_post(&filas_prod[nivel]);
25. break;
26. }
27. }
28. pthread_mutex_unlock(&mutex);
29. return res;
30. }
32. int main() {
33. sem_init(&fila_cons, 0);
34. for(int i=0; i<NUM_NIVEIS; i++) { sem_init(&filas_prof[i], TAMANHO); }
35. pthread_mutex_init(&mutex, NULL);
...
}
Capítulo 7 – Mecanismos de Gestão de Memória
Ex. 1 Considere um computador que pode ser descrito pelas afirmações seguintes:
a) Um programa só pode funcionar nos endereços físicos para onde foi escrito, não podendo ser executado diretamente noutra máquina com um mapa de memória diferente ou mesmo noutro endereço da mesma máquina.
b) Não é possível executar simultaneamente dois programas que tivessem sido preparados para se executarem nos mesmos endereços físicos.
Diga, justificando, se o computador em causa suporta endereçamento real ou virtual.
O computador descrito suporta endereçamento real, i.e., o programa acede diretamente aos endereços de memória (real) fazendo com que: i) o programa apenas se possa executar em máquinas com o mesmo mapa de memória, e ii) o programa não se possa executar simultaneamente com outros programas que usem os mesmos endereços de memória.
Sugestão: Rever Secção secção 7.1.4 - Endereçamento Real e Virtual
Ex. 2 Considere um computador que usa o mecanismo de sobreposição (overlays) em memória real. Descreva como funciona e indique as vantagens e desvantagens deste mecanismo (em comparação com memória real sem overlays).
A utilização de overlays pressupõe que existem dois tipos de segmentos de memória: memória residente e overlays. Ao longo do tempo a aplicação pode pedir ao sistema operativo para carregar overlays para memória primária (fazendo com que outros overlays sejam colocados em memória secondária). Este mecanismo tem a vantagem de ser simples, i.e., requer pouco esforço na gestão de memória por parte do sistema operativo. Por outro lado, tem três grandes desvantagens: i) requer que o programador faça a gestão dos overlays (o que pode resultar em erros); ii) requer que os programas sejam desenhados de forma a dividir a memória necessária em partes separadas (o que pode nem sempre ser fácil); iii) não resolve a limitação do tamanho da memória utilizada (pois o tamanho da memória residente mais o tamanho de um overlay não pode ser superior à memória primária do computador).
Sugestão: Rever Secção 7.3 - Endereçamento Real
Ex. 3 O que motivou o desenvolvimento de programas recolocáveis?
O desenvolvimento de programas recolocáveis foi motivado pelo problema de escalonamento introduzido pelos sistemas multiprogramados com partições fixas. Nestes sistemas, cada programa apenas se pode executar numa partição específica, o que faz com que vários programas tenham que aguardar pela sua vez para se executarem num determinado segmento de memória. O desenvolvimento de programas recolocáveis permite executar programas em qualquer zona de memória.
Sugestão: Rever Secção 7.3 - Endereçamento Real
Ex. 4 Considere a noção de localidade de referência. Diga em que consiste e qual a sua relevância para o mecanismo de gestão de memória virtual.
A noção de localidade de referência pressupõe uma concentração das referências à memória durante certos períodos de tempo. Esta noção é relevante de diferentes formas nos mecanismos de memória virtual. Alguns exemplos: a tradução de endereços virtuais ser feita com a granularidade de uma página ou segmento; a transferência entre memória secundária e primária ser feita com a granularidade de uma página ou segmento; entre outras.
Sugestão: Rever Secção 7.4 - Endereçamento Virtual
Ex. 6 Considere a figura no âmbito da memória virtual paginada.
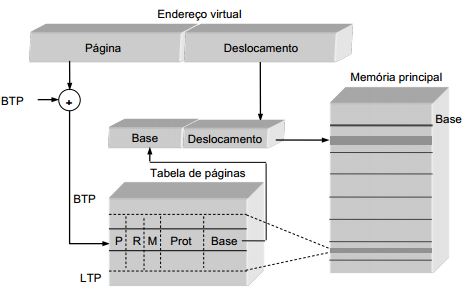
a) Complete a figura (desenhando diretamente na figura) de modo a que a tradução de endereços seja otimizada. Justifique a sua resposta explicando o funcionamento da otimização que indicou.
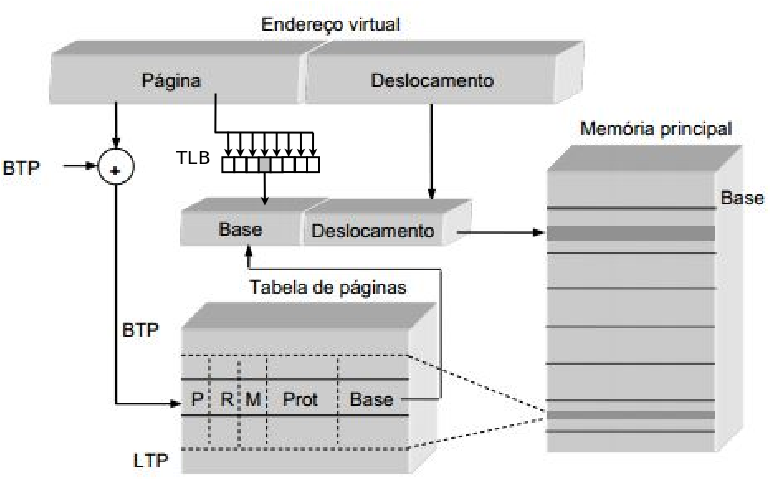
TLB funciona como cache da tabela de páginas, permitindo tradução mais rápida.
b) Diga qual a utilidade de cada um dos elementos da PTE.
P – indica se a página está presente em memória principal
R – indica se a página foi acedida (desde que este bit foi colocado a 0)
M – indica se a página tem conteúdo diferente da cópia em memória secundária
Prot – definem a protecção da página
Base – indica o endereço real do início da página
c) Imagine um computador no qual as páginas virtuais têm uma dimensão de 2048 bytes cada e o espaço de endereçamento virtual é 4 Gigabytes. Diga como é que é constituído um endereço virtual.
Espaço de endereçamento de 4 GBytes = 232 Bytes, logo os endereços virtuais têm 32 bits. Dimensão da página é 211, logo é necessário reservar 11 bits do enredeço virtual para o deslocamento. Logo, cada endereço virtual é constituído por: número de página (21 bits) | deslocamento (11 bits).
d) Diga qual o efeito de uma troca de contexto (context switch) nas estruturas indicadas na figura. Tenha em conta a sua resposta à primeira questão deste grupo.
TLB é limpa pois passa a ser relativa a outro processo (i.e. outro espaço de endereçamento). Os registos BTP e LTP são alterados para apontarem para a tabela de páginas do novo processo em execução.
Sugestão: Rever Secção 7.6 - Paginação
7. Considere um sistema de memória virtual paginada. Qual a razão que obriga a que as instruções sejam recomeçáveis?
As instruções devem ser recomeçáveis pois certas instruções necessitam de aceder a endereços em mais que uma página. Desta forma, um dos endereços pode desencadear uma exceção de gestão de memória quando uma parte da instrução já está em execução. Por esta razão, é necessário que as instruções sejam recomeçáveis.
Sugestão: Rever Secção 7.6 - Paginação
8. Considere o mecanismo de copy-on-write.
a) Em que consiste este mecanismo?
Este mecanismo permite que vários processos partilhem uma ou mais páginas de memória que podem ser acedidas em modo de leitura. Quando acedidas em modo de escrita por um dos processos, leva à cópia das páginas acedidas e à criação de uma cópia das páginas acedidas no espaço de endereçamento de cada processo.
b) Qual a vantagem da sua utilização?
Este mecanismo traz a vantagem de permitir que vários processos partilhem páginas de memória em modo de leitura. Desta forma, é possível minimizar a memória total utilizada pelos processos (já quem a memória pode ser partilhada) e permite reduzir o tempo de criação de processos filhos (já que estes são criados com o conteúdo em memória igual ao pais).
c) Diga um exemplo no qual este mecanismo é usado no Unix.
Este mecanismo é utilizado pelo Unix na criação de processos filhos. Na chamada de sistema fork, o sistema operativo partilha as páginas de memória entre o pai e o filho para permitir a criação mais rápida do processo filho.
Sugestão: Rever Secção 7.5.5 - Partilha de Memória Entre Processos
Capítulo 8 - Algoritmos de Gestão de Memória
Ex. 1 No âmbito da alocação de memória virtual considere a segmentação e a paginação. Indique as vantagens de uma em relação à outra.
Na paginação, a alocação é trivial pois qualquer página livre pode ser utilizada (as páginas livres são geridas utilizando uma FIFO). A alocação de segmentos é mais complexa pois é necessário encontrar um segmento de dimensão igual ou superior à dimensão requerida. Pode ser necessário repartir um segmento em dois e colocar a parte de memória não necessária na lista de segmentos livres.
Sugestão: Rever Secção 8.5 - Análise Comparativa da Segmentação e Paginação
Ex. 2 Considere um sistema de memória virtual. Diga para que serve a área de transferência (swap area).
A área de transferência reside em memória secundária e é utilizada para manter blocos de memória que, por falta de espaço em memória primária, tiveram de ser transferidos para memória secundária. Ou seja, serve para aumentar a capacidade do sistema de memória virtual.
Sugestão: Rever Secção 8.4 - Gestão em Memória Paginada
Ex. 3 Existem três formas de desencadear a transferência de um bloco de memória entre memória secundária e memória primária. Diga quais são e descreva cada uma delas de forma sucinta.
1- A pedido, i.e., quando o programa ou sistema operativo explicitamente pedem o carregamento do bloco.
2- Por necessidade, i.e., quando o programa em execução tenta aceder a um endereço de memória e gera uma falta de bloco.
3- Por antecipação, i.e., quando o sistema operativo carrega blocos de memória que acha que serão acedidos no futuro.
Sugestão: Rever Secção 8.2.3 - Substituição de Blocos
Ex. 4 Num sistema de memória paginada, indique uma solução usada para minorar as faltas de página. Ilustre a sua resposta com um exemplo.
Uma solução normalmente utilizada é a antecipação da transferência de páginas que sejam muito provavelmente acedidas no futuro; por exemplo, páginas de código adjacentes a uma página carregada recentemente serão muito provavelmente acedidas no futuro próximo.
Sugestão: Rever Secção 8.4 - Gestão em Memória Paginada
5. Considere o algoritmo de substituição de páginas denominado NRU, no qual as páginas são organizadas em quatro grupos. Explique em que circunstâncias é que uma página pode pertencer ao “Grupo 1: (R=0, M=1) Não referenciada, modificada”.
Uma página pode pertencer a este grupo se tiver sido modificada e posteriormente o bit R ter sido colocado a zero pelo paginador.
Sugestão: Rever Secção 8.4 - Gestão em Memória Paginada
Ex. 6 Considere o algoritmo de substituição de páginas denominado FIFO. Descreva uma situação, com dois processos, na qual seja clara a desvantagem deste algoritmo.
Imaginando um processo que utilize poucas páginas de memória (embora as utilize regularmente) e outro processo que esteja sempre a aceder a diferentes páginas de memória. Neste cenário, o FIFO representa uma clara desvantagem para o primeiro processo, já que as suas páginas serão periodicamente retiradas de memória apesar de serem acedidas frequentemente.
Sugestão: Rever Secção Secção 8.4 - Gestão em Memória Paginada
Ex. 7 Num sistema paginado, considere a noção de working set de um processo.
a) Diga o que entende por esta noção;
Define-se por espaço de trabalho ou working set o conjunto de páginas acedidas pelo processo num determinado espaço de tempo.
b) Qual a implicação desta noção ao nível da paginação efetuada pelo sistema operativo?
Esta noção implica que o sistema operativo deve assegurar que, para cada processo em execução, deve haver espaço disponível em memória primária para alojar o respetivo espaço de trabalho.
Sugestão: Rever Secção 8.4 - Gestão em Memória Paginada
Ex. 8 Um computador com memória virtual pode entrar em colapso (trashing). Diga o que significa e como se pode evitar.
Um computador pode entrar em colapso se vários processos não tiverem as páginas dos seus espaços de trabalho em memória. Nesta situação, existirão inúmeras faltas de páginas (trashing). Para evitar este problema devem colocar-se em memória apenas os processos cujos espaços de trabalho caibam em memória.
Sugestão: Rever Secção 8.4 - Gestão em Memória Paginada
Capítulo 9 – Sistemas de Ficheiros
Ex. 1 Qual a estrutura do núcleo onde é mantida a dimensão de um ficheiro: diretório, tabela de descritores de ficheiros abertos do processo, tabela de ficheiros abertos global ou inode? Qual a vantagem desta localização relativamente às restantes?
A dimensão de um ficheiro é mantida no inode. Relativamente às outras localizações, são apresentadas possíveis razões para que não faça sentido guardar (em cada uma das localizações alternativas):
- diretório: uma vez que o mesmo inode pode ser referênciado a partir de vários diretórios, uma alteração no tamanho do ficheiro levaria a várias atualizações (uma em cada diretório onde o inode aparece);
- tabela de descritores: esta tabela é local a cada processo, o que faria com que uma atualização no tamanho do ficheiro por parte de um processo levasse a várias atualizações, uma para cada entrada na tabela de descritores do processo relativa ao ficheiro alterado;
- tabela de ficheiros abertos: uma vez que é possível abrir o mesmo ficheiro múltiplas vezes, uma atualização no tamanho do ficheiro por parte de um processo levaria a múltiplas atualizações, uma para cada entrada na tabela de ficheiros abertos relativa ao ficheiro alterado.
Sugestão: Rever Secção 9.3.2.1 - Estruturas Persistentes
Ex. 2 Considere a seguinte sequência de acontecimentos, em que dois processos, P1 e P2, acedem aos ficheiros indicados na seguinte ordem:
P1: f = open(“/users/cnr/dir/f1”); read(f, buf, 50);
P2: g = open(“/users/cnr/dir/f1”); read(g, buf, 100);
P1: h = open(“/tmp/tempfile”);
P1: p = fork(); /* cria um processo filho, P3 */
P1: read(f, buf, 150);
P3: read(f, buf, 200);
Represente graficamente as tabelas de file descriptors por processo, a tabela de ficheiros abertos global do sistema e a tabela de descritores de ficheiros (inodes). Inclua o valor dos índices que indicam a posição.
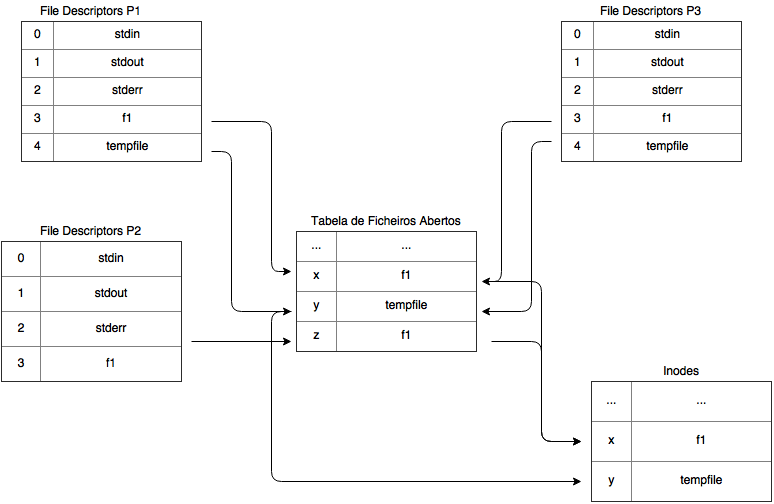
Sugestão: Rever Secção 9.3.2.1 - Estruturas Persistentes
Ex. 3 Considerando blocos de 4KB e referências de 4B, diga quantos acessos a disco são necessários para ler o byte da posição 16.345.324 e o da posição 357 de um ficheiro guardado num sistema de ficheiros ext2. (secção 9.3.2.1)
O byte 16.345.324 está no bloco 3990 (=16.345.324/(4 1024))*
O byte 357 está no bloco 0 (=357/(4 1024))*
Em ext2, cada inode contém 15 referências para blocos, 12 das quais são diretas.
Referências por bloco de índices = Tamanho de Bloco / Tamanho de Referência = 4 1024 / 4 = 1024*
O primeiro bloco de índices contém os blocos 12 a 1036.
O segundo bloco de índices contém os blocos : 1037 a 1049616 (=1037 + 1024*1024)
Para o primeiro cenário são precisos (não contando com o acesso ao inode) 3 acessos a disco: i) acesso ao segundo bloco de índices; ii) acesso ao bloco de índices de segundo grau; acesso ao bloco de dados 3990.
Para o segundo cenário são precisos (não contando com o acesso ao inode) 1 acesso a disco (o bloco de dados 0 está referenciado diretamente pelo inode).
Sugestão: Rever Secção 9.3.2.1 - Estruturas Persistentes
Ex. 4 Considere um sistema de ficheiros do tipo EXT (Linux) no qual cada inode tem as seguintes características. Cada i-node ocupa 64 bytes no total, que incluem:
- 5 referências directas para blocos,
- 1 referência indirecta de 1º nível,
- 1 referência indirecta de 2º nível,
- cada referência para um bloco em disco ocupa 4 bytes (dimensão R),
- cada bloco em disco tem 1024 bytes (dimensão B).
a) Qual a dimensão máxima de um ficheiro?
Dimensão máxima de um ficheiro = B x (5 + B/R + (B/R)^2) = 1024 (5 + 1024/4 + (1024/4)^2) bytes*
b) Quantos blocos são ocupados por um ficheiro com a dimensão de 5130 bytes? Justifique a sua resposta.
Blocos diretos têm a capacidade de 5 1024 bytes = 5120 bytes; logo, é preciso mais um bloco de dados para guardar os restantes bytes o que implica usar 1º nível de indireção.*
Assim, são ocupados 7 blocos: 6 blocos de dados + 1 bloco de índices.
c) Assuma que existe apenas uma partição no disco. Qual o número máximo de ficheiros que este sistema suporta sabendo que a tabela de inodes em disco ocupa, no máximo, X bytes ? Justifique a sua resposta.
Logo, o número máximo de ficheiros é igual ao número máximo de inodes pelo que este número é: X bytes reservados em disco para a tabela de inodes / dimensão de cada inode.
Sugestão: Rever Secção 9.3.2.1 - Estruturas Persistentes
Ex. 5 Considere agora que tem um sistema de ficheiros do tipo FAT no qual cada referência para bloco tem 4 bytes e cada bloco tem 1024 bytes (tal como na questão anterior), e no qual está guardado um ficheiro com 5*1024 bytes ( ou seja 5120 bytes). Conhecendo o índice do 1º bloco do ficheiro, quantas leituras da FAT tem de efetuar até localizar o bloco que contém a posição 5000?
*O byte 5000 está contido no 5º bloco do ficheiro.
Logo é necessário ler da FAT: o índice dos 2º, 3º, 4º e 5º blocos (sequencialmente); ou seja, 4 leituras da FAT.*
Ex. 6 Como compara, em termos de rapidez, o acesso (em leitura ou escrita) ao byte 5000 de um ficheiro que está guardado no EXT (Linux) e na FAT? Justifique a sua resposta.
No EXT o bloco em causa (o último do ficheiro) é acedido mais rapidamente do que na FAT.
Justificação:
- no EXT o bloco é acedido diretamente a partir do inode respetivo;
- na FAT o bloco é acedido depois de percorrer as entradas na FAT de todos os blocos anteriores (4 blocos).
Sugestão: Rever Secção 9.2.2 - Organização Persistente dos Sistemas de Ficheiros
Ex. 7 Considere a figura seguinte que ilustra, à esquerda, o estado da tabela de ficheiros abertos, a tabela de ficheiros abertos do sistema e a tabela de inodes num determinado momento, é à direita ilustra o estado das mesmas tabelas depois do processo P1 executar uma chamada ao sistema syscall1.
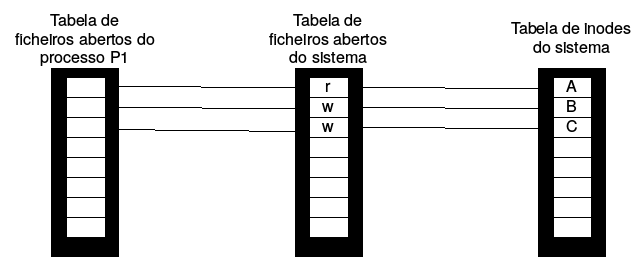
Estado da tabela de ficheiros abertos, a tabela de ficheiros abertos do sistema e a tabela de inodes num determinado momento t1.
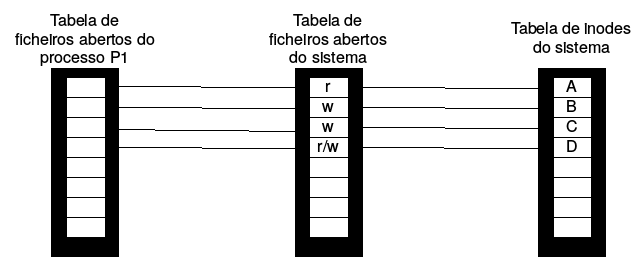
Estado da tabela de ficheiros abertos, a tabela de ficheiros abertos do sistema e a tabela de inodes num determinado t2 > t1.
a) Digal qual foi a chamada sistema correspondente a syscal1 e quais os valores dos argumentos (aqueles que a figura acima lhe permite conhecer).
open(“D”, O_RDWR);
b) Considere que a partir do estado anterior, o processo P1 faz fork criando o processo P2. Complete a figura para representar o estado das tabelas após o fork.
Tabela do processo P2 é igual à do processo P1 apontando assim para as mesmas entradas da tabela de ficheiros abertos do sistema.
c) Considere que a partir do estado anterior, o processo P2 faz exec. Complete a figura para representar o estado das tabelas após o exec.
Nada se altera.
Sugestão: Rever Secção 9.3.2.1 - Estruturas Persistentes
Capítulo 10 - Comunicação Entre Processos
Ex. 1 Considere as duas implementações de mecanismos de comunicação entre processos: memória partilhada, objeto de comunicação do sistema.
a) Compare-as tendo em conta a complexidade da programação da sincronização. Justifique sucintamente.
A comunicação através de memória partilhada requer uma implementação mais complexa pois implica uma sincronização explícita por parte do programador. Isso não acontece com a utilização de objetos de comunicação, pois a sincronização é implicitamente tratada pelo núcleo.
b) Compare-as em termos de eficiência. Justifique sucintamente.
A comunicação via objeto de sistema é menos eficiente pois requer a cópia da mensagem pelo menos duas vezes; uma entre a memória do emissor e o buffer mantido no núcleo, e outra entre o buffer do núcleo e a memória do receptor. Utilizando memória partilhada é possível evitar cópia para o buffer no núcleo, resultando num envio mais eficiente.
Sugestão: Rever Secção 10.1.4 - Implementação do Canal de Comunicação
Ex. 2 No Linux existem mecanismos de comunicação entre processos que são identificados pelos programadores por nomes/endereços pertencentes a diferentes espaços de nomes. Dê exemplos.
1. Pipes com nome e sockets Unix: nome de ficheiro identifica o pipe.
2. Sockets Internet: endereço IP e porto.
(entre outros)
Sugestão: Rever Secção 10.3 - Comunicação entre Processos em Linux
Ex. 3 Considere o seguinte comando shell do Unix resultante do encadeamento de comandos elementares:
ls -l | sort > saida
a) Descreva o resultado do comando;
O comando (ls seguido de sort) começa por listar os ficheiros da diretoria atual (primeiro processo, comando ls); o texto dessa listagem é, por sua vez, ordenado (segundo processo, comando sort); e finalmente escrito no ficheiro ‘saida’.
b) Explique que mecanismos possibilitam este encadeamento de comandos;
Dois mecanismos principais são usados neste tipo de composições de comandos: pipes e redirecionamento de saídas. Neste caso concreto, existe um pipe sem nome utilizado para estabelecer a comunicação entre o processo que executa o comando de listagem ‘ls’ e o processo que executa o comando de ordenação ‘sort’. Usando um pipe, o output do primeiro é usado como input nosegundo. O segundo mecanismo é usado em três momentos: i) para redirecionar o output da listagem para o pipe, ii) para redirecionar o input da ordenação para o pipe, e para iii) redirecionar o output da ordenação para um ficheiro.
c) Descreva sucintamente os principais passos do código que a shell executa para efetuar as operações deste comando encadeado.
Passos principais:
1. Processo shell abre o ficheiro ‘saída’;
2. Processo shell abre um pipe sem nome;
3. Processo shell criar um novo processo filho
Em paralelo:
Processo filho
filho.1 Redireciona o seu stdout para o ficheiro
filho.2 Redireciona o seu stdin para ao extremidade de leitura do pipe
filho.3 Executa o programa ‘sort’
Processo original (pai):
pai.1 Redireciona o seu stdout para a extremidade de escrita do pipe
pai.2 Executa o programa ‘ls’.
Sugestão: Rever Secção 10.3 - Comunicação entre Processos em Linux
Ex. 4 Considere as funções com os protótipos seguintes:
int select(int width, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
int read(int fd, void* buf, int count);
a) Qual o significado do valor de retorno para cada uma destas funções em condições normais?
O select retorna o número de ficheiros que, entre o conjunto de ficheiros indicado nos bitmaps passados como argumentos, estão prontos (segundo cada classe de operações – ler, escrever ou excepções). O read retorna o número de bytes lidos.
b) Pode ocorrer que estas funções retornem prematuramente sem que todos os acontecimentos esperados tenham sido assinalados, ou sem que todos os dados disponíveis tenham sido efetivamente recebidos.
i) Identifique as ocorrências em que este retorno prematuro tem lugar;
No caso do select, duas situações podem ocorrer, um signal ser recebido ou o timeout ter sido alcançado. No caso do read, pode ter sido recebido um signal.
ii) Identifique de que formas isso se reflete nos valores retornados ou modificados pelas funções e no comportamento assumido por estas.
Situação em que select ou read são interrompidos por signal, função retorna erro (-1). Situação em que select expira timeout: retorna 0.
Sugestão: Rever Secção 10.3.2.7- Sincronização e Espera Alternativa
Ex. 5 Explicite as diferenças entre pipes e fifos (também denominados pipes com nome) em Linux. Descreva, para cada um dos tipos de comunicação, qual o seu âmbito de utilização.
Pipes sem nome: comunicação entre processos pai e filho.
Pipes com nome (fifo): comunicação entre quaisquer processos na mesma máquina.
Sugestão: Rever Secção 10.3 - Comunicação entre Processos em Linux
Ex. 6 Considere o ciclo principal de um servidor que faz apenas o eco das mensagens que lhe chegam de clientes. Os clientes podem interagir com o servidor quer com ligações stream TCP quer com datagramas UDP.
for(;;) {
mask = testmask;
select(MAXSOCKS,&mask,0,0,0);
if(FD_ISSET(strmfd,&mask)) {
clilen = sizeof (cliaddr);
newfd = accept(strmfd,(struct sockaddr*)&cliaddr, &clilen);
handleClient(newfd); //Auxiliary function that creates a new process to exchange messages with the client
close(newfd);
}
if(FD_ISSET(dgrmfd,&mask)) echo(dgrmfd);
}
a. Qual a primeira linha em que o servidor se bloqueia?
Na linha 3 (espera no select).
b. Explique o funcionamento da variável mask indicando o valor deve ter na linha 3 antes da invocação do select e que valor ou valores terá quando for testada na linha 4.
A variável mask é um vetor de bits. Na linha 3, os bits no vetor correspondentes aos descritores strmfd e dgrmfd devem estar com valor 1; todos os restantes bits do vetor devem estar a 0. Quando for testada na linha 4, tanto o bits correspondentes a strmfd e a dgrmfd podem ter qualquer combinação de valores (consoante strmfd e dgrmfd estejam ou não prontos para ler).
c. Quantos sockets devem ter sido criados antes do servidor executar esta secção de código? Para que são usados?
Foram criados 2 sockets; um socket stream e um socket datagram. O socket stream é usado para aceitar ligações e receber mensa. O socket UDP é usado para receber mensagens.
d. É criado mais algum socket (além dos que indicou na resposta anterior) na sequência acima? Se sim, para que será usado?
É criado mais um socket na sequência da execução da função accept que, quando retorna, retorna o valor do descritor de um novo sokect TCP. O novo socket é usado para comunicar com o cliente.
e. Se a chamada sistema da linha 8 não existisse o que poderia suceder? Justifique.
O socket newfd não é usado depois desta linha; se não for fechado fica a ocupar uma entrada na lista de descritores do processo em causa.
Sugestão: Rever Secção 10.3 - Comunicação entre Processos em Linux
Extra livro - Programação Concorrente por Troca de Mensagens
Ex. 1 Considere um sistema com um número par de tarefas organizadas num anel, em que cada tarefa conhece o seu antecessor e o seu sucessor. Assuma que, num determinado momento, todas as tarefas têm de enviar uma mensagem ao seu sucessor (e receber uma mensagem do seu antecessor) e que o canal funciona em modo "rendez-vous", ou seja, o emissor fica bloqueado no "enviarMensagem" até que o receptor chame "receberMensagem".
Considere o seguinte código, feito pelo André, que é executado por todas as tarefas:
...
enviarMensagem (myid, proximo, send_buff, strlen(send_buff)+1);
receberMensagem (anterior, myid, receive_buff, BUFFSZ);
....
Neste caso, o sistema entra em inter-bloqueio. Todos os threads chamam "enviarMensagem" antes de chamar "receberMensagem", pelo que todos ficam bloqueados.
A Beatriz e a Cristina arranjaram duas maneiras diferentes de resolver este problema, como se ilustra de seguida.
// Código da Beatriz
...
if (myid == 0) {
enviarMensagem (myid, proximo, send_buff, strlen(send_buff)+1);
receberMensagem (anterior, myid, receive_buff, BUFFSZ);
}
else {
receberMensagem (anterior, myid, receive_buff, BUFFSZ);
enviarMensagem (myid, proximo, send_buff, strlen(send_buff)+1);
}
...
// Código da Cristina
...
if (myid % 2) {
enviarMensagem (myid, proximo, send_buff, strlen(send_buff)+1);
receberMensagem (anterior, myid, receive_buff, BUFFSZ);
}
else {
receberMensagem (anterior, myid, receive_buff, BUFFSZ);
enviarMensagem (myid, proximo, send_buff, strlen(send_buff)+1);
}
...
Qual destas soluções é a mais eficiente, isto é, qual permite completar a troca de mensagens entre todos os threads em menos tempo?
Considere o seguinte exemplo, que ilustra a execução de ambas as soluções com 4 tarefas.
O código da Beatriz vai executar-se da seguinte maneira:
O código da Cristina vai executar-se da seguinte maneira:
T0
T1
T2
T3
Instante 0:
enviarMensagem (0, 1) receberMensagem (0, 1) receberMensagem (1,2) receberMensagem (2, 3)
Instante 1:
receberMensagem (3,0) enviarMensagem (1,2) (vai receber) (em espera)
Instante 2:
(em espera) concluído enviarMensagem (2,3) (vai receber)
Instante 3:
(vai receber) concluído concluído enviarMensagem (3,0)
Instante 4:
concluído concluído concluído concluído
Ou seja, o código da Cristina é mais eficiente, pois enquanto a T0
está a enviar para T1, em paralelo, a T2 está a enviar para T3 (e
depois trocam). Isto permite trocar todas as mensagens em apenas dois ciclos,
para qualquer número de tarefas. No código da Beatriz, T1 tem de
enviar para T2 antes de T2 poder enviar para T3 e assim
sucessivamente. Ou seja, as transferências acabam por ser executadas
sequencialmente, perdendo-se paralelismo.
T0
T1
T2
T3
Instante 0:
enviarMensagem (0, 1) receberMensagem (0, 1) enviarMensagem (2,3) receberMensagem (2, 3)
Instante 1:
receberMensagem (3,0) enviarMensagem (1,2) receberMensagem (1,2) enviarMensagem (0,3)
Instante 2:
concluído concluído concluído concluído